마리아DB
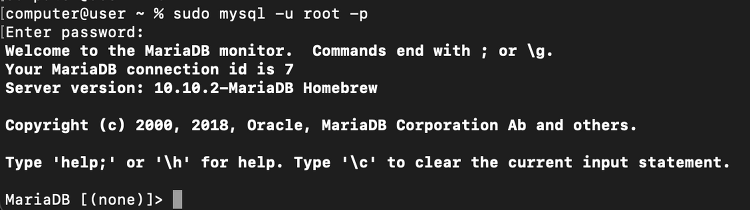
[Mac OS/맥북 M1] MariaDB 설치 / 마리아 DB 개발환경 설정
MariaDB 설치 brew install mariadb 터미널에서 brew 명령어를 이용하여 mariadb를 설치해주자. brew가 뭔지 모르거나 설치되어있지 않다면 아래 글을 참조하면 된다. https://extsdd.tistory.com/417 [Mac OS/맥북 M1] Homebrew 설치하기 Homebrew 란? Mac OS 터미널환경에서 패키지 설치 및 관리를 해주는 소프트웨어다. 파이썬 환경의 pip, nodejs 환경의 npm, 리눅스 환경의 apt-get 과 같은 역할을 한다고 생각하면 쉽다. 설치 방법 Homebrew extsdd.tistory.com MariaDB 시작/정지/상태조회 시작 brew services start mariadb 정지 brew services sop maria..
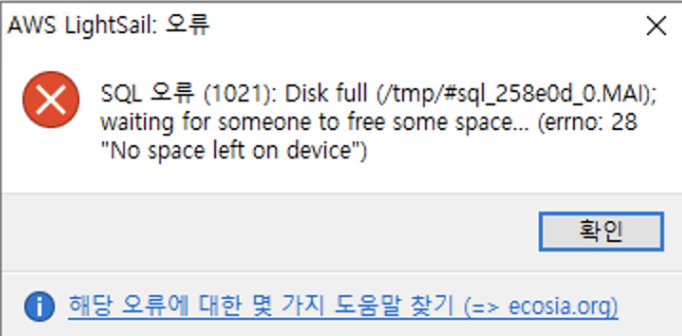
MariaDB SQL 오류(1021) Disk full 해결 방법 / tmp 폴더 “No space left on device” / 라이트세일
이번에는 마리아DB SQL 조회시 담은공간이 없다고 뜨는 Disk Full 문제를 해결해보는 포스팅이다. 현상 어느날 개인적으로 운영하고 있는 서비스의 유입 사용자가 한자리 수 단위로 급감하여 서비스를 확인해보니.. 서버가 다운됐다… 정확히 말하자면 톰캣서버가 다운되진 않았고 서비스들을 점검해보니 DB를 타는 서비스들만 오류가 발생했다. 과거에도 비슷한 사례가 있었다. 그때는 로그성 테이블이 있었는데, 요기가 테이블의 최대치까지 차버려서 문제가 되었는데, 이번에도 그건가 해서 SELECT SQL을 돌려보니 위와 같은 오류가 발생했다. 💡 SQL 오류 (1021): Disk full (/tmp/#sql_258e0d_0.MAI); waiting for someone to free some space… (er..
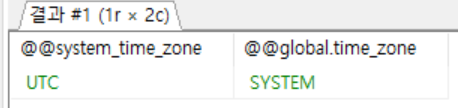
[Maria DB/MySQL] 마리아DB 타임존 변경 system_time_zone
1년간 개인 서버를 운영하다가 now()함수를 돌렸을 때 시간이 맞지 않다는 것을 지금 발견했다..ㅋㅋ아마 작업하고 테스트 했을때 UTC하고 KST하고 9시간 밖에 차이가 안 났기 때문에, 못알아 챈 것 같다. ㅋㅋ select @@system_time_zone, @@global.time_zone; 일단 위 함수 돌렸을 때 시스템 시간이 UTC로 되어있었다. 이걸 한국 시간에 맞게 바꿔보자 방법 1. 임시 방편 - Maria 재부팅 하면 초기화 mysql_tzinfo_to_sql /usr/share/zoneinfo | mysql -u root -p mysql 터미널을 이용해 우리 서버로 접속하고 위 명령어를 입력해주자. 아마 비번치라고 나오는데 비번 쳐주면 된다. 이 작업을 해야 시스템에서 사용하는 ..
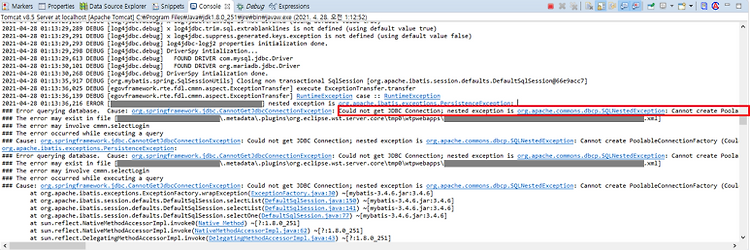
[Maria DB] 스프링 원격 DB 접속 오류 / Cannot create PoolableConnectionFactory (Could not connect to address)
문제 발생 오랫만에 서버 이전을 하고 DB 타겟을 바꾸고 서비스를 실행하는데 DB 연결이 안되는 문제가 나타났다. Cannot create PoolableConnectionFactory (Could not connect to address= (host=xxx.xxx.xxx.xxx)(port=3306)(type=master) : Connection refused: connect) 당시 로그는 위처럼 찍혔다. Could not get JDBC Connection 어쩌구..DB 커넥션을 맺은 JDBC 객체를 정상적으로 리턴받지 못한 모양이다. 왜지!? 전이랑 똑같이 했는데 왜 안돼! telnet 목적지IP 포트 회사에서 IF 서비스들을 많이 다뤄서 그런지 내 기계적으로 내 PC에서 텔넷부터 찍어봤다. 오잉....
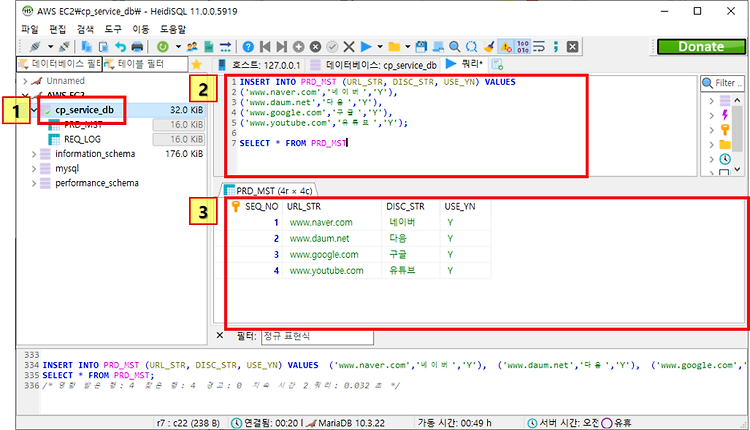
[Maria DB] AWS EC2 원격 서버 마리아 DB 접속 / HeidiSQL / 데이터 삽입 / 테이블 생성
https://extsdd.tistory.com/123 [아마존 AWS EC2] #3 스프링/전자정부프레임워크 프로젝트 AWS에 FileZilla로 배포하기 / 메이븐 빌드 / 자 여태까지 만들었던 프로젝트를 아마존에 배포할 시간이다. https://extsdd.tistory.com/113 [Spring/eGov ] #8 이클립스에서 마리아DB 데이터 조회하기 / MyBatis / 컨트롤러 Controller / 서비스 / DAO / http.. extsdd.tistory.com 자 저번시간까지 했던걸 보면, 만들었던 스프링 프로젝트가 AWS EC2 인스턴스에 올라갔다. 이후 페이지를 요청했지만, 원격 서버에 마리아 DB만 설치해놓고 DB에 테이블과 데이터를 생성해놓지 않았기 때문에 오류를 뱉어냈다. 오..

[아마존 AWS EC2] 마리아 DB 원격접속 설정하기 / HeidiSQL 원격 접속 / plink.exe / SSH 연결 / 인스턴스
과거 포스팅을 보면 EC2 인스턴스를 생성할때 3306포트에 대한 방화벽 설정은 다 해줬음으로 바로 연결을 시도해보자. 1. HeidiSql 을 이용한 원격 접속 HeidiSql을 실행하고 11시방향에 있는 새 연결 아이콘을 눌러주자! 다음으로 좌측 하단 7시방향에 있는 신규 버튼(1)을 눌러주자. 그리고 2번쪽으로 가서 해당 세션의 이름을 정해주자. 3번박스로가서 MySQL (SSH tunnel) 로 유현을 변경해주고 4번 호스트 ip는 127.0.0.1 로 가만히 둔다. 5번 박스에 아까 위에서 root 계정으로 접속을 하자. 6번은 따로 안건드렸다면 AWS EC2에 올라간 포트번호가 3306일테니 그대로 둔다. 따로 바꾼사람만 바꿔주면 된다. 자 위에 1번 박스에 있는 SSH터널 탭으로 들어가자 P..

[아마존 AWS EC2] 마리아 DB 설치 / Mysql Root 계정 초기 비밀번호 설정
PuTTY를 이용해 설치하려는 EC2 서버에 접속한다. 1. 마리아 DB 설치 sudo apt-get install mariadb-server 위 명령어를 통해 마리아DB 최신버전을 받아주자. 자 1번 박스를 보면 위 명령어를 실행했고 2번 박스를 보면 ㄹㅇ 설치할꺼냐는 물음에 Y치고 엔터를 눌러 동의해주자. 쭈르륵 뭔가 설치되면서 끝난다. 2. 마리아 DB Root 계정 비밀번호 설정 mysqladmin -u root -p password '비밀번호' 위 명령어를 입력해 비밀번호를 초기화 해주자! 입력후 Enter Password:가 나오는데 비번을 똑같이 쳐주고 엔터를 눌러주자. 3. Maria DB 접속 mysql –u root -p 위 명령어를 이용해 root 계정으로 마리아DB에 접속하자! 짜잔..
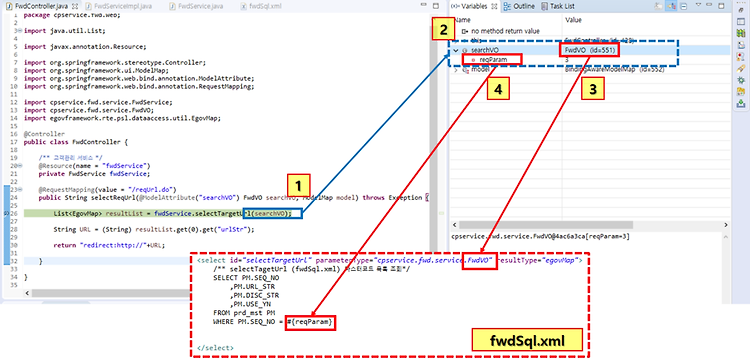
[Spring/eGov] #9 이클립스에서 마리아DB 데이터 Select 과정 디버깅하기 / 디버깅 방법 / Debug / 디버그
https://extsdd.tistory.com/113 [Spring/eGov ] #8 이클립스에서 마리아DB 데이터 조회하기 / MyBatis / 컨트롤러 Controller / 서비스 / DAO / https://extsdd.tistory.com/112 [Spring/eGov ] #7 스프링, 전자정부프레임워크 샘플 예제- 마이바티스(MyBatis)로 마리아 DB 연동하기 / https://extsdd.tistory.com/102 [Spring/eGov ] #6 웹 서비스 만들기 2.. extsdd.tistory.com 자 저번시간까지 우리가 만든 마리아 DB를 내 스프링 프로젝트와 연동했고, 테스트로 데이터도 넣고, 컨트롤러에서 select까지 해보면서 포스팅을 마쳤다. 오늘 알아볼껀 실제로 어떻게..