스프링
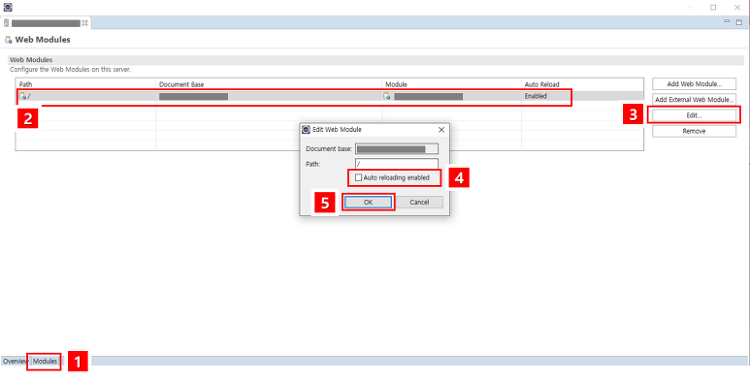
[Spring] 톰캣 재시작 없이 Java 파일 변경 적용하기 - Spring Loaded [Maven]
톰캣으로 스프링 프로젝트를 개발하면서 은근 시간을 많이 잡아먹는 톰캣 재부팅.. JAVA 소스 한글자만 수정해도 반영되려면 톰캣을 재부팅 해야반영된다. 새로운 기능 개발을 하면서 이것저것 테스트할 때 수십법 재부팅을 해야하는데.. 이게 개인 프로젝트 급이면 재부팅 머 10~30초 이내라지만, 기업급 프로젝트는 재부팅도 꽤나 많은 시간을 차지한다..재부팅 눌러놓고 커피나 뽑으러 가거나 했었지만 이게 은근 흐름을 끊고 그 몇분을 다 모아보면 꽤나 많은 시간이 허비 된다는 것을 느꼈다 ㅋㅋ... 그래서 java파일 변경 후 톰캣 재부팅이 필요없는 Spring Loaded 적용하는 법을 알아보자. 1. Spring Loaded 설치 https://mvnrepository.com/artifact/org.s..
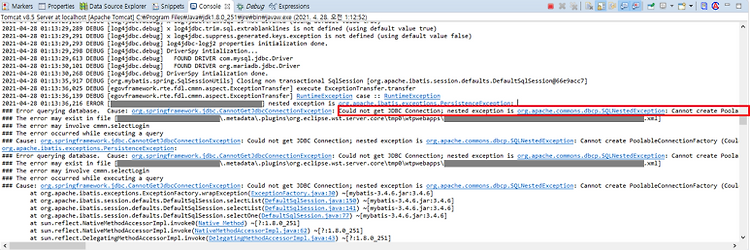
[Maria DB] 스프링 원격 DB 접속 오류 / Cannot create PoolableConnectionFactory (Could not connect to address)
문제 발생 오랫만에 서버 이전을 하고 DB 타겟을 바꾸고 서비스를 실행하는데 DB 연결이 안되는 문제가 나타났다. Cannot create PoolableConnectionFactory (Could not connect to address= (host=xxx.xxx.xxx.xxx)(port=3306)(type=master) : Connection refused: connect) 당시 로그는 위처럼 찍혔다. Could not get JDBC Connection 어쩌구..DB 커넥션을 맺은 JDBC 객체를 정상적으로 리턴받지 못한 모양이다. 왜지!? 전이랑 똑같이 했는데 왜 안돼! telnet 목적지IP 포트 회사에서 IF 서비스들을 많이 다뤄서 그런지 내 기계적으로 내 PC에서 텔넷부터 찍어봤다. 오잉....

[WAS 이슈 해결 #1] java.lang.OutOfMemoryError: GC overhead limit exceeded 로 인한 Tomcat 서버 다운 / CPU 사용량 폭증
최근 운영중인 웹서비스가 비규칙적으로 다운되는 현상이 있었는데, 발생했던 문제와 그 문제를 해결하는 과정에 대해서 포스팅을 해보려고 한다. 서버 운영을 하는 실무자들에게 도움이 되었으면 좋겠다. 문제 발생 첫 발생이 3월 초쯤 이었던가?.. 운영중인 웹 서비스가 종종 다운되는 현상을 겪었다. 운영 서버에 요청을 보내면 처리되지 않다가 결국 몇 분 뒤 Tomcat 서버가 죽어 위처럼 Service Unavailable 메시지를 띄었다. 보통 부하 분산과 장애에 대비해 WAS를 이중화 해놓기 때문에 WAS하나가 죽어도 다른 WAS가 처리해 줄껀데, 브라우저가 응답대기 상태도 아니고 Service Unavailable 을 띄운걸로 봐서는 WAS두개가 모두 죽은 것 같았다. 어떤 문제가 있었던걸까? 여태..

[아마존 AWS EC2] #3 스프링/전자정부프레임워크 프로젝트 AWS에 FileZilla로 배포하기 / 메이븐 빌드 / Maven Build / Install / 파일질라
자 여태까지 만들었던 프로젝트를 아마존에 배포할 시간이다. https://extsdd.tistory.com/113 [Spring/eGov ] #8 이클립스에서 마리아DB 데이터 조회하기 / MyBatis / 컨트롤러 Controller / 서비스 / DAO / https://extsdd.tistory.com/112 [Spring/eGov ] #7 스프링, 전자정부프레임워크 샘플 예제- 마이바티스(MyBatis)로 마리아 DB 연동하기 / https://extsdd.tistory.com/102 [Spring/eGov ] #6 웹 서비스 만들기 2.. extsdd.tistory.com 여기까지 못따라온 사람은 위 글까지 마치고 오면 될 것 같다. 메이븐 프로젝트 / Maven 자 지금까지 정자정부프레임워크(..
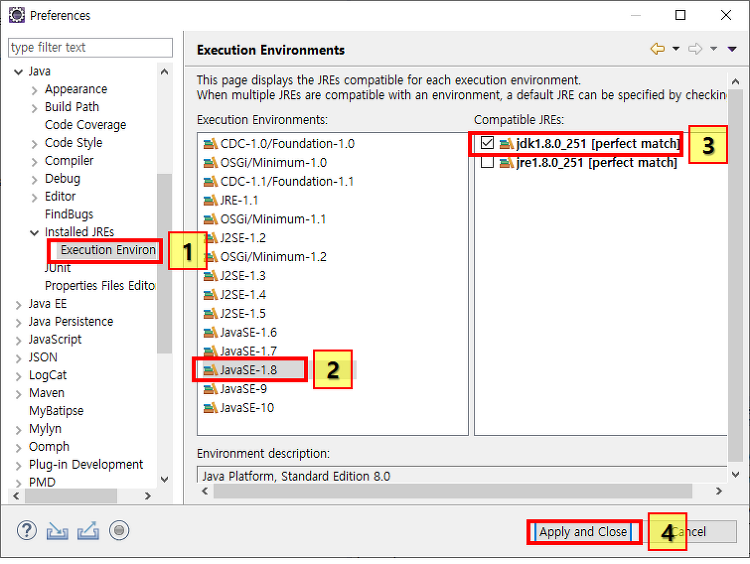
[Spring/eGov] 메이븐 빌드 실패 / Failed to execute goal / Perhaps you are running on a JRE rather than a JDK
자 메이븐 빌드를 했는데 위처럼 JRE대신 JDK를 써보라는 오류가 발생했다. 원인은 간단하다. JRE로 빌드를 못한다는거다. JDK로 경로를 다시 잡아주면 된다. 1. Installed JREs 재설정 이클립스 상단 윈도우 버튼(1)을 누른뒤 Preferences버튼을(2) 눌러주자! 1. 자바 탭을 누른다. 2. Installed JREs 탭을 누른다. 3. 여기를 보면 지금 Path가 JRE로 잡혀있다.. 분명... 나랑 환경설정하면서 JDK도 설치했는데 왜..! JRE로 잡고 있는거야 ㅡㅡ.... 그래서.. 수동으로 Path를 잡아줘야한다. 4. Add 버튼을 눌러주자. 1. 창이나오면 Standard VM으로 나와있을텐데 그냥 두면된다. 2. 바로 Next를 눌러 넘어가주자. 1. 자 여기서 J..

[Spring/eGov] #10 DB 조회 쿼리 및 결과 Console 창에 출력하기 / Log4j2.xml 수정 / 콘솔 로그
https://extsdd.tistory.com/114 [Spring/eGov] #9 이클립스에서 마리아DB 데이터 Select 과정 디버깅하기 / 디버깅 방법 / Debug / 디버그 https://extsdd.tistory.com/113 [Spring/eGov ] #8 이클립스에서 마리아DB 데이터 조회하기 / MyBatis / 컨트롤러 Controller / 서비스 / DAO / https://extsdd.tistory.com/112 [Spring/eGov ] #7 스프링, 전자.. extsdd.tistory.com 자 우리가 저번까지 DB에서 데이터를 조회해보고 잘 되는지 확인헀다. 하지만 쿼리를 조회하더라도 Console창에 찍히는게 없어서, 실제로 어떤 구문이 실행됐는지, 결과는 나왔는지 알 ..
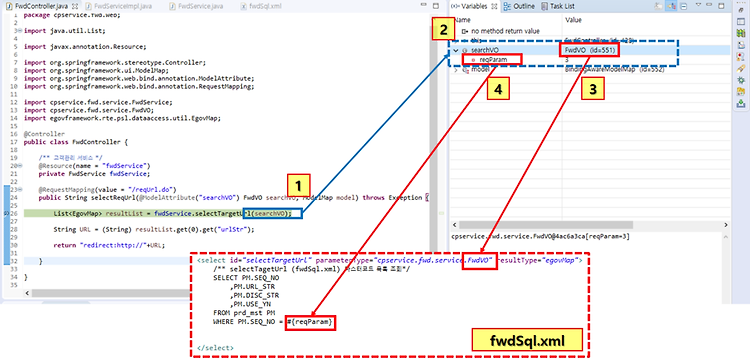
[Spring/eGov] #9 이클립스에서 마리아DB 데이터 Select 과정 디버깅하기 / 디버깅 방법 / Debug / 디버그
https://extsdd.tistory.com/113 [Spring/eGov ] #8 이클립스에서 마리아DB 데이터 조회하기 / MyBatis / 컨트롤러 Controller / 서비스 / DAO / https://extsdd.tistory.com/112 [Spring/eGov ] #7 스프링, 전자정부프레임워크 샘플 예제- 마이바티스(MyBatis)로 마리아 DB 연동하기 / https://extsdd.tistory.com/102 [Spring/eGov ] #6 웹 서비스 만들기 2.. extsdd.tistory.com 자 저번시간까지 우리가 만든 마리아 DB를 내 스프링 프로젝트와 연동했고, 테스트로 데이터도 넣고, 컨트롤러에서 select까지 해보면서 포스팅을 마쳤다. 오늘 알아볼껀 실제로 어떻게..
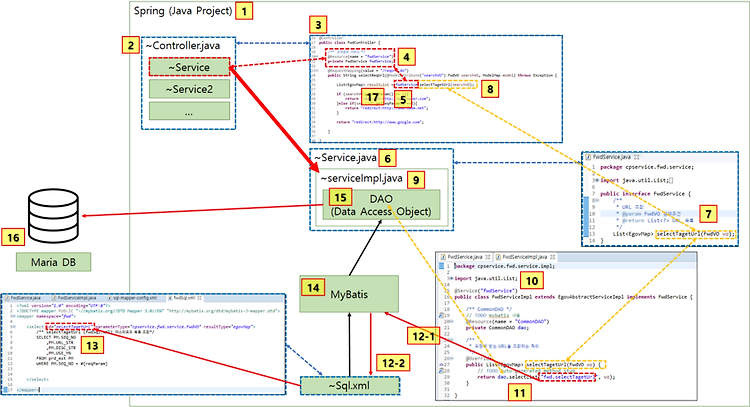
[Spring/eGov ] #8 이클립스에서 마리아DB 데이터 조회하기 / MyBatis / 컨트롤러 Controller / 서비스 / DAO / 원리 / 구조 / Sql.xml
https://extsdd.tistory.com/112 [Spring/eGov ] #7 스프링, 전자정부프레임워크 샘플 예제- 마이바티스(MyBatis)로 마리아 DB 연동하기 / https://extsdd.tistory.com/102 [Spring/eGov ] #6 웹 서비스 만들기 2 / 요청 URL 파라미터 가져오기 / Debug 방법 / 디버깅 하는법 / @Model extsdd.tistory.com 자 우리가 마지막으로 했던게 사용자 요청 URL.. extsdd.tistory.com 자 저번 시간까지 이클립스와 Maria DB를 MyBatis라는 친구로 연동을 시켰다. 아. 전에 MyBatis가 먼지 설명을 안했는데 간단하게 설명하자면 과거에 JAVA코드로 쿼리로 DB에 있는 데이터를 조회하려고..