![[딥러닝] #3 머신러닝이 무엇인지 알아보자! / 인공지능과의 관계 / 지도학습 / 비지도학습 / 강화학습](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbguLkv%2FbtqG61RNeDh%2F9vFsYsdtKins6NcG7wYaFk%2Fimg.png)
저번시간까지 간단하게 인공지능과 인공지능의 역사에 대해서 알아봤다. 이제 본격적으로 머신러닝이 무엇인지 알아보자.
머신러닝 (Machine Learning)
= 스스로 학습하여 성능을 향상시키는 기술

일단 인공지능과 머신러닝의 관계를 먼저 집고 넘어가자, 자. 머신러닝은 인공지능의 한 분야로써, 기계 스스로가 학습하여 더 나은 성능을 내도록 하는 기술이다. 이 기술이 인공지능이라는 큼 범주에서 뻗어나온 소범주인 것이다.
머신러닝은 학국말로 기계학습이라고하는데 이 기계학습이란게 뭘까? 쉽게 말하면 프로그램에게 입력들을 주고 출력을 확인한후 그 출력에따라 프로그램이 로직을 조정하여 다음 입력을 주었을때 더 좋은 결과가 나오도록 프로글매 스스로가 본인의 로직을 수정하며 개선해나가는 것이다.
스스로 로직을 수정한다?

비전공자들도 그렇고 코딩을 좀 해봤던 전공자들도 저 위 의미가 좀 헷갈릴 수 있다. 스스로 로직을 수정한다고? 우리가 알고있는 전통적인 프로그램은 인간들이 로직을 짜놓고 예를들어 입력값 a가 10보다 크면 1을 출력해! 그게 아니면 0을 출력해!!
input a
if( a > 10 ){
print : 1
}else{
print : 0
}이렇게 로직을 짜고 돌리면 딱 저 로직에 의해서만 결과가 나온다. 그런데 이 로직을 컴퓨터가 수정한다고? 맞다. 뭐 굳이 말하면 프로그램 자체가 저 코딩되어 있는 소스 자체를 바꾸고 그런건 아니다. 수학적인 모델링을 통해 수치들을 저장해놓고 해당 수치들을 업데이트시켜 최적의 값을 찾아내는 방식이다.
예를들어 입력에 3을 입력했는데 결과가 0이네? 두번째 입력에 11을 입력했는데 결과가 1이네? 세번째 입력에 10을 입력했는데 결과가 0이네? 3개의 입력을 했을때의 결과를 봐선 입력이 10보다 크면 1을 반환하고 작으면 0을 반환하는 것을 알아냈다. 그럼 프로그램이 기준을 input>10 이라고 정한다. 혹여나 나중에 다른 입력과, 출력이 들어와도 위에 말한 수학적 모델을 통해 이 기준 값을 프로그램이 스스로 수정하는 것이다.
정리하자면 과거의 전통적인 프로그램은 사용자가 룰을 입력하여 아웃풋을 내는 거였으면, 머신러닝은 아웃풋을 입력받아 자기 스르로 룰을 만드는 것이다. 이제 이해가 조금 되려나..!?
이렇게 머신러닝에도 여러 종류들이 있다. 로지스틱 회귀, 선형 회귀, 인공신경망(딥러닝) 등, 일단은 이 머신러닝의 학습 종류에 대해서 집고 넘어가 보자
머신러닝에서 훈련의 의미
머신러닝에서는 훈련이라는 단어가 많이쓰인다. 아니, 필수라고 해도 과언이 아니다. 그럼 머신러닝에서 훈련이라는 단어으이 의미는 무엇일까? 우리가 알고 훈련의 의미 그대로다. 위에 머신러닝의 동작 방식을 잠깐 살펴보면, 입력을 주고 프로그램이 그 입력과, 출력을따져보고 규칙을 스스로 수정한다고 했다. 이 한번의 과정이 한번의 훈련이다.
100개의 입력, 출력을 주고 규칙수정이 100번 일어났다면 이건 100번 훈련했다고 한다. 즉, 프로그램이 스스로 개선하도록 여러가지 입력(문제)과 출력(답)을 주고 기준을 수정하는 과정이 바로 훈련이다. 말그대로 머신러닝은 기계가 학습하는 과정이기 때문에 이 학습과정에서 훈련과정은 필수라고 할 수 있다.
지도 학습
= supervised learning
= 입력과 타깃으로 모델을 훈련
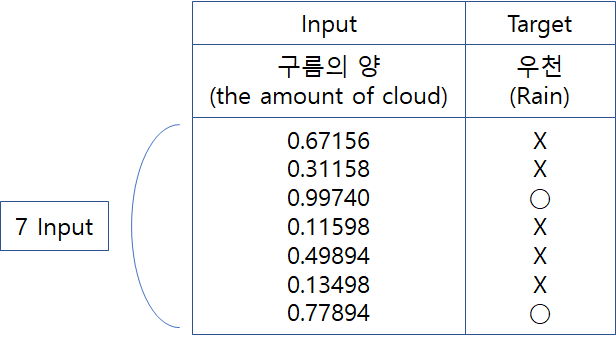
지도 학습은 말그대로 이해해보면 인간이 프로그램을 지도해주는 것이다. 위 데이터 예시를 보면 프로그램한테 구름의 양에따라서 실제로 비가 내렸는지에 대한 과거 데이터들을 넣어준다 이걸 훈련데이터라고 부른다. 총 7개의 데이터를 넣어주고 구름의 양이 67%면 비가 안내렸고, 다음 31%였을때 비가 안내렸고 99%였을떄 비가 내렸고.. 총 7번의 데이터를 순차적으로 넣어주며 프로그램이 훈련한다.
결국 7번의 훈련을 거쳐 플그램은 대략 구름의 양이 70% 보다 많으면 비가 오고, 그 이하면 비가 안온다의 기준을 만들어 낸다. 데이터가 7개 밖에 없지만 여기에 수억개의 훈련 데이터가 들어오면 이 기준은 아주 정교해진다.
이렇게 과거의 입력(Input)과 출력(Target)에 대한 데이터들을 주고 이 데이터의 패턴을 확인하여 기준을 만드는게 바로 지도학습이다. 그리고 이 훈련된 데이터에 새로운 입력을 넣으면 그 예상 결과를 나타내 주는게 바로 지도 학습!
→ 지도 학습의 한계
지도학습에서 가장 중요한건 훈련데이터다. 정교한 프로그램이 될려면 거대한 훈련데이터가 필요한데 이런 데이터를 수집하거나 만드는 과정도 만만치 않으며, 이 데이터중에 오차가 큰 데이터가 있을때도 문제가 된다.
가장 큰 문제는 입력들이 새로 들어왔을때 실시간으로 모델이 최신화 되지 않는다는 것이다. 새로 입력된 데이터를 포함하여 새로 훈련시켜야한다는 것인데, 즉, 모델이 한번 만들어지면 그 모델에대한 예상값만 반환할뿐 환경변화에 적응하기 어렵다는 단점을 가지고 있다.
비지도 학습
= unsupervised learning
= 타깃이 없는 데이터로 훈련

비지도 학습은 지도학습과 반대로 타깃데이터가 없다. 즉 입력만 있고 결과 데이터가 없이 주어진다는 것이다. 이런 비지도 학습을 이용하는 하는 예씨로 그룹 분류가 있다.
그룹을 만들기 전까지는 어떤 그룹도 존재하지 않고, 어떤 그룹이 있을지도 모르기 때문에 타깃(target)이 없는 것과 같다. 타깃이 없는 상태에서 프로그램은 해당 입력들을 특서엥 맞게 분류하여 군집(Target)을 만든다.
이런 방식이 바로 비지도 학습이다.
강화 학습
= reinforcement learning
= 결과에 대해 상과 벌을 준다.
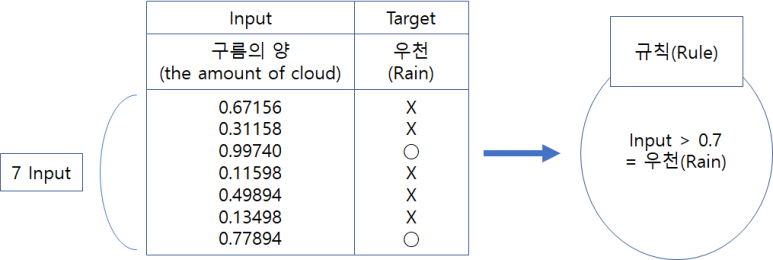
아까 잠깐 보았던 지도학습을 보면, 입력들을 이용해 규칙(Rule)을 만들어 냈다. 하지만, 한번 만든 모델에 입력을 넣어 그 예상 결과만 받아볼뿐 입력의 성격이 바뀌면 여기에는 적응하지 못하는 한계를 가지고 있었다. 하지만 강화학습을 이용하면 위 문제를 어느정도 해결 할 수 있다.
강화학습은 입력을 가지고 타겟을 평가한다. 그래서 맞으면 상을주고, 틀리면 벌을주면서 가지고 있는 규칙을 조정한다. 이러면 나중에 입력들의 성격이 바뀌어도 상벌에 의해서 규칙이 그 환경에 맞게 적응할 수 있는 것이다.
위 내용을 하나의 모델로 만든 것을 에이전트라고 부른다. 에이전트의 목표는 최대한 많은 보상을 받는 것이 목표다. 구글의 알파고도 이런 강화학습을 이용해 만들어졌다.
[딥러닝] #3 머신러닝이 무엇인지 알아보자! / 인공지능과의 관계 / 지도학습 / 비지도학습 / 강화학습
#딥러닝 #머신러닝 #인공지능 #관계 #지도학습 #비지도학습 #강화학습
'IT > 머신러닝 | 딥러닝' 카테고리의 다른 글
| [딥러닝] #5 퍼셉트론(Perceptron)에 대해서 알아보자 / 인공신경망(ANN) 퍼셉트론과 뉴런의 차이점 / 편향 b(bias)의 의미 (3) | 2020.08.27 |
|---|---|
| [딥러닝] #4 인공신경망(ANN)과 딥러닝(Deep Learning)에 대해 알아보자! / 뉴런(Neuron)의 동작 원리 (0) | 2020.08.25 |
| [딥러닝] #2 인공지능의 역사 / 퍼셉트론의 XOR 문제 / 인공신경망(Artificail Neural Network : ANN) (0) | 2020.08.23 |
| [GPT-3] OPEN AI 자연어 처리 API GPT-3 소개 및 사용 신청하기 (0) | 2020.08.23 |
| [딥러닝] #1 인공지능이 무엇인지 알아보자 / 강 인공지능 vs 약 인공지능 (0) | 2020.08.16 |