종료
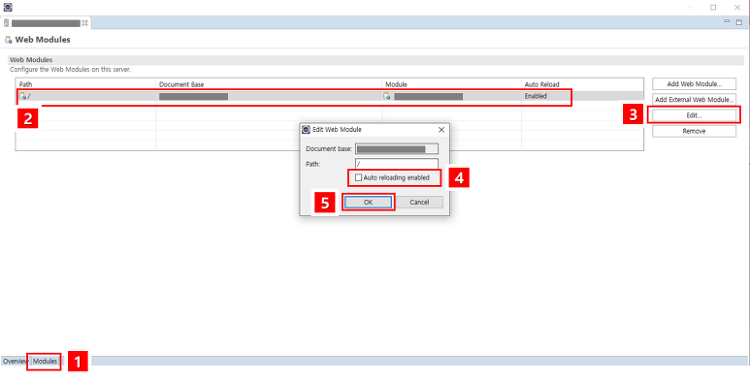
[Spring] 톰캣 재시작 없이 Java 파일 변경 적용하기 - Spring Loaded [Maven]
톰캣으로 스프링 프로젝트를 개발하면서 은근 시간을 많이 잡아먹는 톰캣 재부팅.. JAVA 소스 한글자만 수정해도 반영되려면 톰캣을 재부팅 해야반영된다. 새로운 기능 개발을 하면서 이것저것 테스트할 때 수십법 재부팅을 해야하는데.. 이게 개인 프로젝트 급이면 재부팅 머 10~30초 이내라지만, 기업급 프로젝트는 재부팅도 꽤나 많은 시간을 차지한다..재부팅 눌러놓고 커피나 뽑으러 가거나 했었지만 이게 은근 흐름을 끊고 그 몇분을 다 모아보면 꽤나 많은 시간이 허비 된다는 것을 느꼈다 ㅋㅋ... 그래서 java파일 변경 후 톰캣 재부팅이 필요없는 Spring Loaded 적용하는 법을 알아보자. 1. Spring Loaded 설치 https://mvnrepository.com/artifact/org.s..
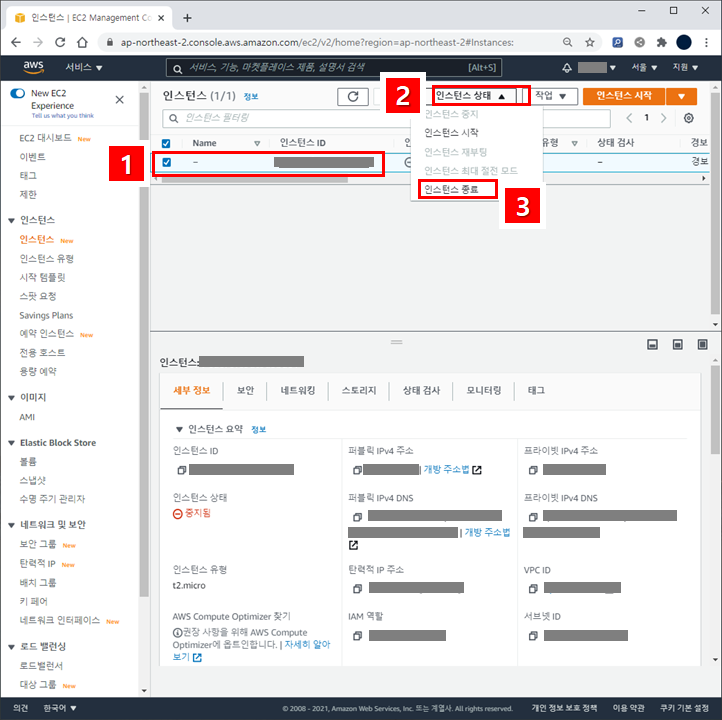
[아마존 AWS EC2] 서버 인스턴스 삭제하기 / 프리티어 종료! / Elastic IP 삭제
이번에 아마존 EC2 인스턴스를 12개월 동안 무료로 사용할 수 있는 프리티어 기간이 끝난다는 메일을 받았다. 아무생각 없이 영원히 이용할 수 있을 것 같았던 EC2가.. 끝이라니..! 무료 사용 종료는 2020년 4월 30일.. 이번달이 지나고 나서 온디멘드 요금으로 전환된다. 그래서 그냥 유료로 기존 EC2 서버를 운용 할 것인가. 아님 그냥 서비스를 종료할까, 아니면 다른 서버로 이주해서 계속 서비스를 할 것인가 고민을 많이 했다. 고민끝에 서버를 이전하기로 했고, 기존 EC2 서버는 더 이상 요금이 발생하지 않도록 삭제하기로 했다. 1. EC2 인스턴스 종료 및 삭제 인스턴스 중지 EC2 인스턴스를 삭제하기 전에 실행중이라면 인스턴스를 종료해주자. 1. EC2 대시보드에서 인스턴스를 눌..

[WAS 이슈 해결 #1] java.lang.OutOfMemoryError: GC overhead limit exceeded 로 인한 Tomcat 서버 다운 / CPU 사용량 폭증
최근 운영중인 웹서비스가 비규칙적으로 다운되는 현상이 있었는데, 발생했던 문제와 그 문제를 해결하는 과정에 대해서 포스팅을 해보려고 한다. 서버 운영을 하는 실무자들에게 도움이 되었으면 좋겠다. 문제 발생 첫 발생이 3월 초쯤 이었던가?.. 운영중인 웹 서비스가 종종 다운되는 현상을 겪었다. 운영 서버에 요청을 보내면 처리되지 않다가 결국 몇 분 뒤 Tomcat 서버가 죽어 위처럼 Service Unavailable 메시지를 띄었다. 보통 부하 분산과 장애에 대비해 WAS를 이중화 해놓기 때문에 WAS하나가 죽어도 다른 WAS가 처리해 줄껀데, 브라우저가 응답대기 상태도 아니고 Service Unavailable 을 띄운걸로 봐서는 WAS두개가 모두 죽은 것 같았다. 어떤 문제가 있었던걸까? 여태..